STARK 算法解析(第 2 部分: 有用的“工具”)
有限域在整个密码学中无处不在,因为它们与计算机天然兼容。例如,它们不会产生上溢或下溢错误,而且有限域中的每个元素也都有一个对应的有限比特的表示形式。
构造一个有限域的最简单方法是选择一个素数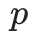 ,得到
,得到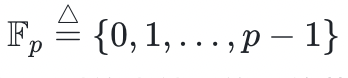 ,并使用整数运算法则来“类比定义”一般的加法和乘法运算,最后将结果模以约束结果的取值范围,使得运算结果仍落在此数域内。减法相当于把被减数与减数的相反数相加,其中相反数相当于乘以
,并使用整数运算法则来“类比定义”一般的加法和乘法运算,最后将结果模以约束结果的取值范围,使得运算结果仍落在此数域内。减法相当于把被减数与减数的相反数相加,其中相反数相当于乘以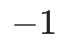 (在有限域内
(在有限域内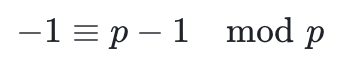 )。类似地,除法相当于被乘数乘以乘数的逆元。其中,逆元可以通过扩展欧几里得算法求得,该算法在输入两个整数
)。类似地,除法相当于被乘数乘以乘数的逆元。其中,逆元可以通过扩展欧几里得算法求得,该算法在输入两个整数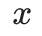 和
和 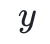 后,返回它们的最大公因数
后,返回它们的最大公因数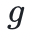 以及裴蜀定理所匹配的对应系数
以及裴蜀定理所匹配的对应系数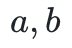 ,使得
,使得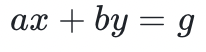 。事实上,只要
。事实上,只要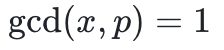 ,
,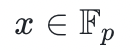 的逆元就是
的逆元就是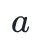 ,因为
,因为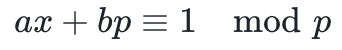 。有限域中元素的幂可以用平方-乘算法来计算,该算法在由指数扩展出的比特位上进行迭代,在每次迭代中对累加器变量进行平方,如果该比特位已被设置,则需额外乘以基底元素。
。有限域中元素的幂可以用平方-乘算法来计算,该算法在由指数扩展出的比特位上进行迭代,在每次迭代中对累加器变量进行平方,如果该比特位已被设置,则需额外乘以基底元素。
为了构造 STARKs,我们需要具有以下特殊结构的有限域:(笔者注:实际上,StarkWare 团队刚发表的一篇精彩的论文展示了如何在任何有限域中应用同样的方法,无论它是否具有特殊结构。本教程会使用结构化有限域,以简单的方式来解释构造。)它需要包含一个阶为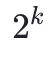 (
(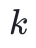 是一个足够大的数)的子结构。我们考虑素域,其定义模数的形式
是一个足够大的数)的子结构。我们考虑素域,其定义模数的形式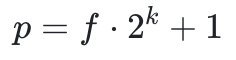 ,其中
,其中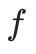 是使得该数成为素数的协因子。在这种情况下,群
是使得该数成为素数的协因子。在这种情况下,群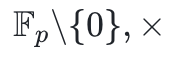 有一个阶为的子群。实际上,我们可以将这个子群等同于均匀分布在复数单位圆上的个点。
有一个阶为的子群。实际上,我们可以将这个子群等同于均匀分布在复数单位圆上的个点。
下面介绍用于计算乘法逆元的方法,它是以扩展欧几里得算法为起点展开的。

将关于域的逻辑与关于域中元素的逻辑区分开是有意义的。为此,域元素会包含一个域对象来作为合适的域;这个域对象实现了相应的算术运算。此外,python 支持运算符重载,因此我们可以重新利用一般算术运算符来进行域中的算术运算。
通用的实现域是很好的。然而,在本教程中,除了具有
个元素的域,我们将不会使用任何其他的域,该域具有足够大的阶为“二的幂”的子群。


除了确保阶为“二的幂”的子群的存在性,代码还需要为用户提供“整个乘法群”的以及“阶数为‘二的幂’的子群”的生成元。这样一个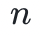 阶子群的生成元将被称为次本原单位根。
阶子群的生成元将被称为次本原单位根。

最后,该协议要求支持对域元素进行随机和伪随机采样。为此,用户需提供随机字节,域逻辑将它们变成域元素。用户应注意提供足够数量的随机字节。

单变量多项式是一个单一形式的未定元的非负幂加权和。我们把多项式写成各项之和的形式,即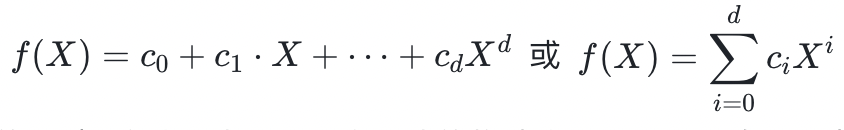 ,因为 a)未定元
,因为 a)未定元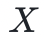 的值通常是未知的;b)这种形式强调了多项式的构建来源,因此更有助于获得直观性的认识。在这些表达式中,
的值通常是未知的;b)这种形式强调了多项式的构建来源,因此更有助于获得直观性的认识。在这些表达式中,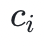 是多项式的系数,
是多项式的系数,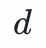 是多项式的阶数。
是多项式的阶数。
单变量多项式在证明系统中是非常有用的,因为适用于多项式系数向量之间的关系,可以扩展到多项式在更大的域中的值。如果两个多项式是相等的,它们在任何地方都是相等的;而如果它们是不相等的,它们几乎在任何地方都是不相等的。通过这一特点,单变量多项式将对大向量的断言,归约为对其相应多项式在一小部分足够随机的点上的值的断言。
单变量多项式的代数实现从重载标准算术运算符开始,以计算多项式系数向量的正确函数。其中,有一个重要的问题需要特别注意。多项式的首项系数不可能是零,因为首项系数指的是最高度数的非零项的系数。然而,最终实现的系数向量可能有尾部的零,这些零应该被忽略。此时,阶数函数 就派上用场了;它的值被定义为“忽略尾部零后的系数向量的长度”减 1。这也意味着零多项式的阶数会为 -1,虽然实际上用 -∞ 表示更合适。
当想要实现多项式的除法时,事情变得有点棘手。教科书算法背后的原理是:在每一次迭代中,你都要将被除数乘以一个“正确的项”,以便消去首项。一旦没有这样的“正确的项”存在,你就获得了余数。


在基本的算术运算方面,最好有一个“求幂映射”,主要是为了便于符号上的简单表示而不是为了提高性能。

如果一个多项式不允许在任意给定点上计算它的值,那么这个多项式就是毫无意义的。对于 STARKs,我们需要更为通用——在一个整环上的多项式求值,而不仅仅是在一个单一的点上求值。性能现在还并不是需要考虑的问题,所以下面的实现遵循一个简单的迭代方法。反方面,STARKs 也需要多项式插值,其中 x 坐标是另一些已知范围内的值。性能不是一个现在要考虑的问题,因此,目前标准的拉格朗日插值已经足够了。

说到整环 :有一件事经常出现,就是计算在其上会“消失”的多项式。任何这样的多项式都是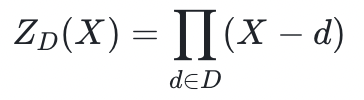 的倍数, 其为最低阶首一多项式,在
的倍数, 其为最低阶首一多项式,在 内所有点上取值为 0,这个多项式通常被称为“消失多项式”,有时也被称为“归零多项式”(zerofier)。本教程更倾向于第二个描述方式。
内所有点上取值为 0,这个多项式通常被称为“消失多项式”,有时也被称为“归零多项式”(zerofier)。本教程更倾向于第二个描述方式。

另一个有用的工具是缩放多项式的能力。具体来说,这意味着从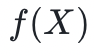 的系数中获得
的系数中获得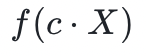 的系数向量。当被定义为在
的系数向量。当被定义为在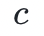 的幂上取值的序列(即
的幂上取值的序列(即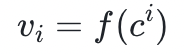 )时,这个功能就特别有用,那么代表相同的数值序列,只是都平移了一位。
)时,这个功能就特别有用,那么代表相同的数值序列,只是都平移了一位。

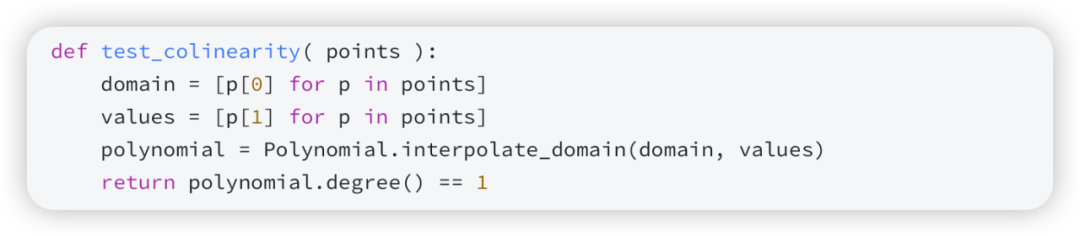
单变量多项式模块定义的最后一个函数预示着 FRI 协议中的一个关键操作,即测试三个点是否落在同一条线上——它有一个花哨的名字:共线性。
在进入下一节之前,值得停下来注意的是,对于有限扩域,或者简单说——扩域,所有要提前说明的内容都已经说完了。一个有限域只是一个配备了加法和乘法运算符的集合,这些运算符的运算规则符合高中所学的代数规则,例如,每个非零元素都有一个逆元、任意两个非零元素相乘不可能得到零,等等。有两种方法可以得到这样的域:
从整数集开始,将任何加法或乘法的结果模去一个给定的质数
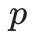 。
。从有限域上的多项式集合开始,利用不可约多项式
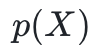 来化简任何加法或乘法的结果(化简方式:将所得结果模)。当一个多项式不能被分解为两个较小的多项式的乘积时,它就是不可约的,其定义类似于素数。
来化简任何加法或乘法的结果(化简方式:将所得结果模)。当一个多项式不能被分解为两个较小的多项式的乘积时,它就是不可约的,其定义类似于素数。
重点是,只要后续步骤使用先前步骤的扩域,就可以在比密码学编译步骤更小的域中进行算术化操作。具体来说,例如:EthSTARK 在由 62 位素数定义的有限域上进行操作,但 FRI 步骤在其二次扩域上进行操作,以达到更高的安全级别。
本教程不使用扩域,对该主题的详细介绍超出了本教程讨论范围。
多变量多项式将单变量多项式推广到多个未定元——不仅仅是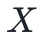 ,而是
,而是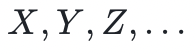 单变量多项式有助于将关于“大向量”的大断言化简为关于随机点“标量值”的小断言,多变量多项式有助于阐明计算完整性所满足的算术化约束。
单变量多项式有助于将关于“大向量”的大断言化简为关于随机点“标量值”的小断言,多变量多项式有助于阐明计算完整性所满足的算术化约束。
例如,考虑算术几何平均数,它被定义为序列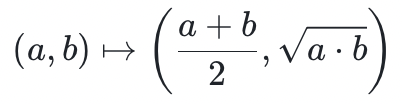 的第一或第二坐标的极限(两极限最终收敛于相同的数),其中
的第一或第二坐标的极限(两极限最终收敛于相同的数),其中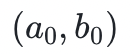 为起始点。(笔者注:证明有限域元素的代数-几何平均数的计算完整性没有任何意义,不用太在意,这里提及它仅仅是用于举例)为了证明这个过程的几次迭代的完整性,需要的是一组多变量多项式,它捕获到一次正确迭代的约束条件,这些约束条件与当前状态
为起始点。(笔者注:证明有限域元素的代数-几何平均数的计算完整性没有任何意义,不用太在意,这里提及它仅仅是用于举例)为了证明这个过程的几次迭代的完整性,需要的是一组多变量多项式,它捕获到一次正确迭代的约束条件,这些约束条件与当前状态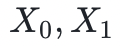 和后续状态
和后续状态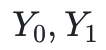 相关。在这句话中,“捕获”一词的意思是,如果计算是完整的,那么多项式的求值结果为零。这些多项式可能通过以下的形式出现:
相关。在这句话中,“捕获”一词的意思是,如果计算是完整的,那么多项式的求值结果为零。这些多项式可能通过以下的形式出现: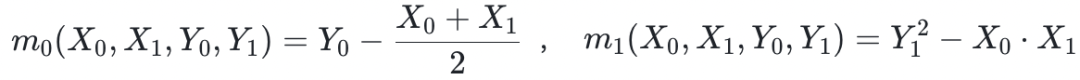 (此处应当注意:
(此处应当注意: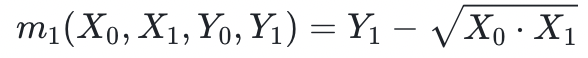 实际上并不是一个多项式,尽管它有相同个数的零)
实际上并不是一个多项式,尽管它有相同个数的零)
实现单变量多项式的结构是一个系数列表,多变量多项式的结构是一个将“指数向量”映射到“系数”的字典。只要这个“字典”映射的系数为零,该条映射关系就应当被忽略。同前文实现步骤一样,首先重载标准算术运算符、基本构造函数和标准功能。

由于多变量多项式是单变量多项式的泛化拓展,所以需要有一种方法来继承已经在前一类定义的逻辑。函数 lift 通过将单变量多项式“提升”为多变量多项式来实现这一目的。第二个参数是与“单变量未定元”相对应的“未定元的索引”。

接下来是求值。这个方法需要的参数是一个标量元组,因为它需要给每一个未定元赋值。然而,值得关注的是 STARK 中使用的一个特征——求值是符号化的:不是在“标量元组”中对多变量多项式求值,而是在“单变量多项式的元组” 中进行求值。其结果不是一个标量,而是一个新的单变量多项式。

在交互式公开抛币协议中,验证者的消息是从任何人都可以采样的分布中获取的纯随机数。我们的目标是得到一个非交互式协议,在不牺牲安全性的情况下,证明同样的事情。Fiat-Shamir 转换实现了这一点。
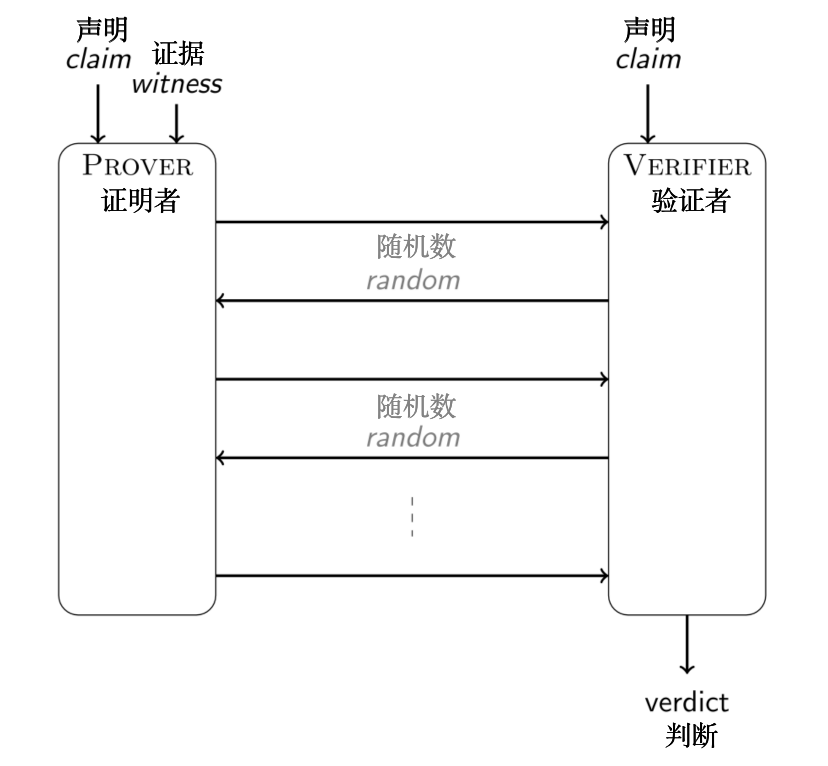
事实证明,为了达到足够对抗恶意证明者的安全性,按照交互式协议的规定随机生成验证者的消息是多余的。只要验证者的消息难以被证明者预测就足够了。哈希函数具有确定性,但同时满足输出的难预测性。因此,直观上看,如果用哈希函数的伪随机输出取代验证者真实产生的随机数,该协议仍然是安全的。必须要限制证明者,使得其无法对进入哈希函数的输入进行操控,否则他可以一直试,直到找到一个合适的输出。将到需要验证者消息之时之前的协议“对话脚本”设定为输入就足够了。
这正是 Fiat-Shamir 转换背后的思想:将验证者的随机消息替代为到此之前协议“对话脚本”的哈希值。Fiat-Shamir 启发式指出,这种转换保留了安全性。在哈希函数的理想化模型随机预言机模型中,这种方法的安全性是可以证明的。
Fiat-Shamir 转换带来了第一个工程上的挑战。交互式协议是以信道(channel)的形式来描述的,这个信道将消息从证明者传给接收者、从接受者传给证明者。Fiat-Shamir 转换将这种“通信交流”序列化,同时实现对证明者的描述,使其抽象化。Fiat-Shamir 转换确实修改了验证者的描述,使其成为确定性的。
证明流是用于模拟这种信道的一个有用的概念。与编程中的常规流不同的是,其中并没有向另一个进程或计算机进行实际的传输,发送方和接收方也不需要同时操作。这也不是一个简单的队列,因为证明者和验证者可以访问一个函数,通过哈希他们对信道的“视图”来计算伪随机性。对于证明者来说,这个“视图”是到目前为止发出的所有消息的整个列表。对于验证者来说,这个“视图”是迄今为止读取的消息的子列表。验证者的消息不会被添加到列表中,因为它们可以被确定性地计算出来。给定证明者的消息列表,序列化是直接的。非交互式证明正是这种序列化。
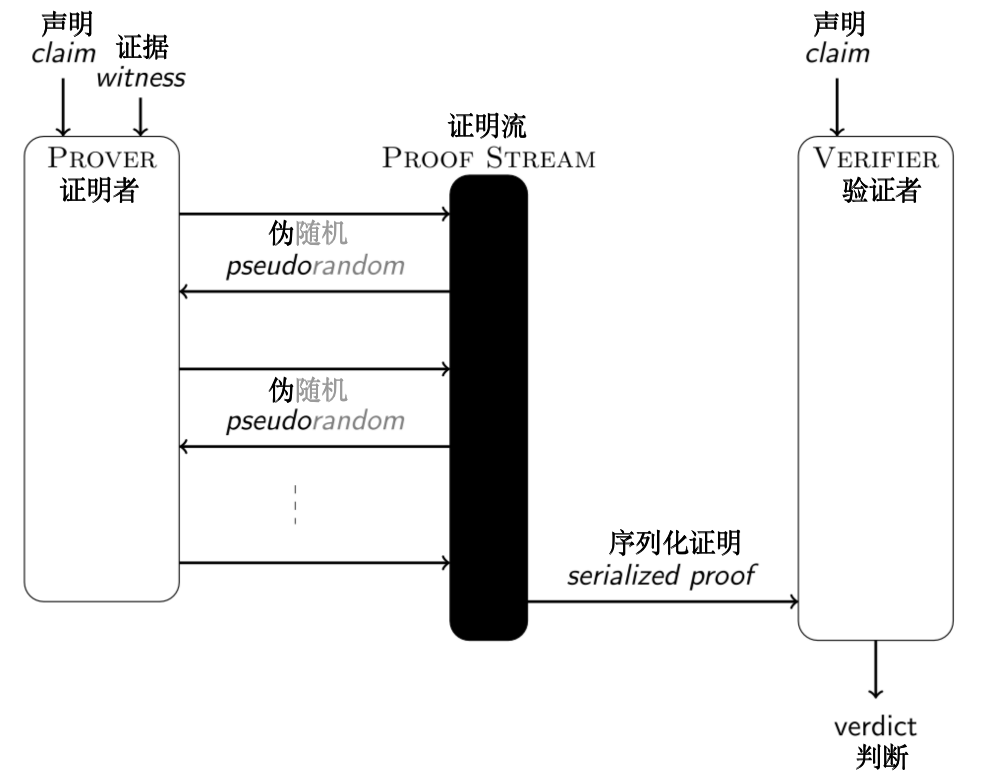
在实现方面,需要一个支持 3 种功能的 ProofStream 类:
将对象从队列中推入和拉出的操作。此队列是由一个带有读取索引的列表模拟的。每当一个元素被推入时,它就被附加到列表中。每当一个元素被拉出,读取索引就会增加 1。
序列化和反序列化。了不起的 Python 库
pickle实现了这个功能。Fiat-Shamir 。哈希的实现主要通过以下两步:首先,序列化整个队列或者队列的第一部分;第二步,应用 SHAKE-256。其中,SHAKE-256 允许一个可变的输出长度,特定的应用程序可以根据自己的需求设置这个长度。默认情况下,输出长度被设置为 32 字节。

Merkle 树是一个由抗碰撞哈希函数构建的向量承诺方案。(笔者注:在某些情况下,如基于哈希的签名中,抗碰撞可能会过强,更基础的安全概念,如抗第二原像可能就足够了)具体来说,它允许用户对一个由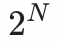 个元素组成的数组进行“承诺”,其中:
个元素组成的数组进行“承诺”,其中:
“承诺”是一个单一的哈希摘要,这个承诺是绑定的——它用于防止用户改变数组,如果用户想要改变数组,则用户首先必须攻破哈希函数;
对于任何索引
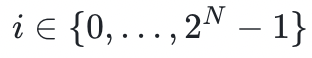 ,“承诺”的数组中第
,“承诺”的数组中第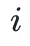 位置的值,可以用额外
位置的值,可以用额外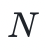 个哈希摘要来证明。
个哈希摘要来证明。
具体来说,二叉树的每个叶子都代表一个数据元素的哈希值。每一个非叶子的节点代表其两个子节点拼接后的哈希值。Merkle 树的树根是“承诺”。一个“成员身份”证明由从指定的叶子节点到根节点的路径上的所有节点的兄弟节点组成。这个兄弟节点的列表被称为认证路径,并向验证者在路径的每一步提供了个哈希函数完整的原像,最终对根节点进行校验。
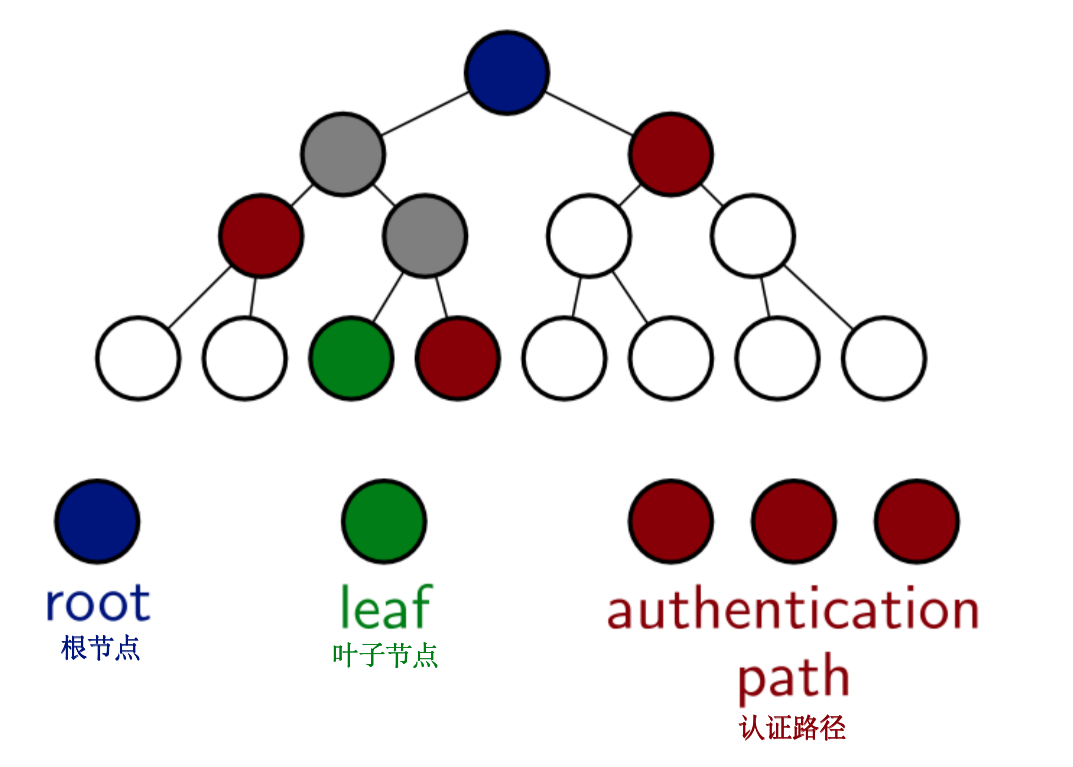
这个结构的实现需要提供以下三个功能:
commit - 计算一个给定数组的 Merkle 根
open - 计算 Merkle 树中一个指定叶子节点的认证路径
verify - 验证一个给定的叶子节点是否是给定索引的承诺向量中的一个元素。
如果性能不是一个要考虑的问题(在本教程中,性能的确不是要考虑的问题),这些功能的递归本质会产生一个奇妙的函数化实现。

这种函数化实现忽略了一个重要方面:数据对象一般都不是哈希摘要。所以为了将这些函数与现实世界的数据结合起来使用,必须先对现实世界的数据元素进行哈希。这种用于预处理的哈希是 Merkle 树逻辑的一部分,所以 Merkle 树模块需要扩展实现此功能。

上一篇:Polygon Hermez:使用零知识技术为以太坊可扩容
zCloak Network 是基于波卡生态的隐私计算服务平台,使用 zk-STARK 虚拟机为通用计算进行零知识证明的生成与验证。基于独创的自主权数据和自证明计算技术,可以让用户在无需对外发送数据的情况下,实现对数据的分析和计算。通过波卡跨链消息传递机制,可以为波卡生态内的其它平行链以及其它公链提供数据隐私保护支持。项目会采用“零知识证明即服务”的商业模式,打造一站式的多链隐私计算基础设施。
原文出自 《Anatomy of a STARK》系列,原文链接见“阅读原文”
转载请注明原文与本文出处及翻译团队 zCloak Network
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表本站的观点或立场
您可能感兴趣
-
 一个月换 5 个高管,Coinbase 在重构什么?
一个月换 5 个高管,Coinbase 在重构什么?作者:Zhou,ChainCatcher本月以来,Coinbase 的领导班子经历了一轮密集调整。 首席法务官 Paul Grewal 将于 7 月 31 日离任,转投一家初创公司,由内部提拔的 Mo
-
 多年来“最不确定”的一次!今晚的美联储会给“惊吓”吗?
多年来“最不确定”的一次!今晚的美联储会给“惊吓”吗?作者:华尔街见闻今晚的美联储决议大概率仍是“按兵不动”,但市场真正担心的不是基准情景,而是一次罕见的意外加息,或一次措辞足够鹰派的暂停。 北京时间7月30日凌晨2:00,美联储将公布最新利率决议。本次
-
 SK海力士的最新财报,能成为存储芯片的救命稻草吗?
SK海力士的最新财报,能成为存储芯片的救命稻草吗?昨晚,美股芯片板块再度遭遇惨烈抛售。SK海力士和美光双双重挫近9%,闪迪更是暴跌14%。这种跌幅本该足以登上财经头条,但如今甚至快让人产生"审美疲劳"了——芯片股大跌,正在从"新闻"变成"日常"。市场
-
 中国光刻机也要进入DeepSeek时代?美股又要面临抛压了吗?
中国光刻机也要进入DeepSeek时代?美股又要面临抛压了吗?昨晚,美股芯片板块再度遭遇惨烈抛售。 闪迪收跌11%,SK海力士跌逾7%,股价正式跌破149美元的IPO发行价。就连一向稳健的龙头英伟达,也大跌5%。 而今天上午,恐慌情绪蔓延过了太平洋——韩国股市再
-
 当加密货币驶入「监管深水区」:为何合规阵痛是 Web3 走向全球普及的必经之路?
当加密货币驶入「监管深水区」:为何合规阵痛是 Web3 走向全球普及的必经之路?近年来,全球加密货币市场似乎步入了一个前所未有的「强监管周期」。从今年 5 月英国针对部分头部加密货币交易所实施精准的资产冻结,到 7 月底欧盟正式祭出第 21 轮制裁方案并对多家加密平台实施广泛的交
-
 交给曲线,别和周期对抗:宏观分析大师 Raoul Pal 的加密 10 年投资复盘
交给曲线,别和周期对抗:宏观分析大师 Raoul Pal 的加密 10 年投资复盘作者:Raoul Pal,Real Vision 联合创始人兼 CEO 原标题:《Where Crypto Fits in the Exponential Age》 编译:胡韬,ChainCatche
-
 Visa 最新研究: 1.1 亿笔交易背后,Agent 支付正在重构互联网商业
Visa 最新研究: 1.1 亿笔交易背后,Agent 支付正在重构互联网商业作者:Tim Conard(Visa 链上数据负责人)、Lucas Shin(Artemis 数据与研究) 编译:佳欢,ChainCatcher 前言 Artemis 是链上数据领域的分析平台,Vis
-
 CLARITY 法案的“最后一公里”为何走不通?
CLARITY 法案的“最后一公里”为何走不通?作者|Odaily 星球日报 jk《数字资产市场结构法案》,(Digital Asset Market Clarity Act,即 CLARITY 法案)自 2025 年 7 月 17 日以 294
- 成交量排行
- 币种热搜榜
 泰达币
泰达币 比特币
比特币 以太坊
以太坊 USD Coin
USD Coin Solana
Solana 瑞波币
瑞波币 Ronin Network
Ronin Network 币安币
币安币 World Liberty Financial USDv
World Liberty Financial USDv 莱特币
莱特币 艾达币
艾达币 狗狗币
狗狗币 大零币
大零币 Wormhole
Wormhole 比特现金
比特现金 SHIB
SHIB UNI
UNI OKB
OKB AR
AR ICP
ICP DOT
DOT LUNC
LUNC YGG
YGG DYDX
DYDX LPT
LPT ETC
ETC