分形扩容:又一个区块链扩容方向?
L3 和 L2 之间的交易实际上是可以原子组合的
原文:Fractal Scaling
作者:polynya
编译:Evelyn,W3.Hitchhiker
原用标题(译后):一文了解新应用:分形扩容
封面:Photo by Siora Photography on Unsplash
StarkWare 已经很好地介绍了这个话题,最近 Vitalik 也出了一篇关于 layer 3 的详细文章。那么,在这里,我有什么要补充的吗?我一直认为我没有,这就是为什么我从来没有写过这个话题的原因 —— 自从我第一次与 StarkWare 的人讨论这个话题以来,已经过去了 10 个月。但是今天,我想我也许可以从不同的角度来漫谈这个问题了。
首先要了解的是,"web2 "现在在全世界的 100,000,000 台服务器上运行。而"Web3 "是一个相当愚蠢的 meme,因为它被明确是 "web2 "的一个小众子集。但是,让我们假设这种区块链网络可以创造其小而可持续的(但有利可图的)利基市场(niche),吸引那些严格要求分布式信任模型和相对最小的计算的场景(即没有什么比拥有定制硬件的超级计算机更能实时编码数百万个视频了)。假设我们只需要 "web2 "的 0.1% 的计算能力。那就是需要 100,000 台服务器来建立一个小的利基市场。
现在,让我们考虑一个高 TPS 的单片链,如 BNB Chain 或 Solana。虽然按比特币这样的安全和去中心化优先的链来说,它似乎令人印象深刻,但它必然是一个中端服务器,因为你必须让成百上千的实体保持同步。今天,一个更高端的服务器将是 128 核,而不是 12 核;有 1TB 内存,而不是 128GB,等等。随即,1 台普通的服务器就能满足需求,这似乎是很荒谬的。事实上,一款真正的链上游戏要想获得成功,可能需要多个高端服务器,而这些服务器的计算能力则需要是 Solana 的 10 倍。
下一步是 rollups。虽然专门的执行层的设计空间很广,而且在不断发展,但我说的是具有 1-of-N 信任假设的 rollups。由于 1-of-N 的假设(相对于 51% 的大 M 而言),不再需要运行成千上万的节点。因此,在其他情况下,rollup 可以升级到更高性能的服务器。ZK rollups 有一个特别的优势,因为许多节点可以简单地验证有效性证明(所以你可以只需要一个拥有少量全节点的高性能服务器)。是的,你需要验证者(prover),但这些证明只需要生成一次,而且随着软件和硬件的进步,证明时间也在不断减少。
不过,在某些时候,rollup 节点会成为一个瓶颈。目前,最强大的瓶颈是状态增长。让我们假设状态增长的问题得到了解决,那接下来的事情就有点模糊了,根据场景的不同,会有一些带宽/延迟或计算的组合。根据Dragonfly 的基准,即使是像 AMM swaps 这样非常温和的计算密集度低的用例,BNB Chain 在 195 TPS 和 Solana 在 273 TPS 时就达到了这个极限。如前所述,由于需要同步的节点少得多,rollup 可以把这个问题推得进一步,以缓解带宽瓶颈,但很快你就会遇到计算瓶颈。这实际上是由 Solana 的 devnet 所证明的,它的运行配置更类似于 rollup,它的 TPS 是 425 而不是 273。
然后是并行化。像 StarkNet 和 Fuel V2 这样的 rollups 项目都专注于并行执行;而像 Optimism 这样的其他团队的路线图上也计划有这一点。理论上,你可以在多个核心上的不同收费市场上与不同的用户运行多个不同的 dapp,但在实践中,这里所获得的收益预计是相当有限的。MEV 机器人将在任何时候访问所有的状态,而费用将根据链上的金融活动来设定。所以,在现实中,你会有一个核心的瓶颈。这是智能合约链的一个基本限制。这并不是说并行化没有帮助(它会有帮助的)。例如,StarkNet 的 optimistic 并行方法,肯定是一个净正的方法(这是因为,如果交易不能被并行化,它就会返回到主核心)。
64 核 CPU → 64 倍潜在吞吐量的想法是非常错误的。首先,如上所述,并行执行只在某些情况下有帮助。但更大的问题是,64 核 CPU 运行时的单线程性能大大降低。例如,64 核 EPYC 以 2.20 GHz 或 3.35 GHz(boost)的时钟频率运行;而基于相同架构的 16 核 Ryzen 9 的时钟频率为 3.4 GHz,boost 最高至 4.9 GHz。因此,对于许多交易来说,64 核的 CPU 实际上会明显慢一些。顺便提一下,最新的第七代 Ryzen 9 将在几周后发布,在每个核心的基础上提升到 5.7 GHz ,速度提高了 15% —— 所以,是的,随着时间的推移,每个个体的计算能力确实都有提高。但远没有许多人认为的那么快(如今若想翻一倍,需要 4-5 年的时间)。
因此,由于快速主核心的重要性,你可以扩展到最大的 16 核,如上图所示。(顺便说一下,这也是为什么你的廉价的 Ryzen 5 在游戏中提供的 FPS 是 64 核 EPYC 的 2 倍)。但是这些核心不太可能被利用到,所以我们最多只能看到 2-5 倍的提升。对于任何计算密集型的东西,我们最多考虑几百个 TPS,以实现最快的执行层。
一个充满吸引力的解决方案可能是 ASIC VM,所以基本上你有一个巨大的单核,比普通的 CPU 核快 100 倍。一位硬件工程师告诉我,把 EVM 变成一个快如闪电的 ASIC 是非常简单的,但是会花费数亿美元。也许这对于解决像 EVM 一样多的金融活动来说是非常值得的?缺点是我们需要先解决状态管理和有效性证明(即 zkEVM)的僵化规范 —— 但也许是 2030 年代要考虑的问题。
回到此时此刻 —— 如果我们将并行的概念提升到一个新的水平会怎样?与其把所有东西都塞进一台服务器,为什么不把事情扩展到多台服务器上呢?这就是我们得到 Layer 3 的地方。对于任何计算密集型应用来说,特定于应用的 rollup 是相当必要的。而这样也有几个好处:
- 为一个应用程序进行微调,虚拟机成本为零
- 没有 MEV,或有限的 MEV,通过简单的解决方案来减轻有害的 MEV
- 专门的收费市场,也是 2)有很大的帮助。此外,你可以有新的收费模式,以获得最佳的用户体验
- 为特定目的选择微调硬件(而智能合约链总是有一些不适合你的应用的瓶颈)
- 解决交易质量的三难问题 —— 你可以不收取,或是收取忽略不计的费用,但仍然可以通过有针对性的 DDoS 缓解措施来规避垃圾信息。这样做的原因是,用户总是可以退出到结算层(2 或 1),保持抗审查。
那么,为什么不是特定于应用的 L1,如 Cosmos zones、Avalanche subnets 或 Polygon supernets?答案很简单:社会经济和安全碎片化。让我们重新审视一下问题陈述:如果我们有 100,000 台服务器,每台都有自己的验证者集(这显然是永远不会成功的)。如果你有重叠的验证者,每个验证者将需要运行多个超级计算机;或者如果每个验证者都有自己的验证者集,那将会变得非常不安全。目前来说,欺诈证明或有效性证明是唯一的方法。为什么不采用类似于 Polkadot 的或 NEAR 的分片?这里存在严格的限制,例如,每个 Polkadot 分片只能做几十 TPS,而且它的分片只会有 100 个。当然,他们有条件转向分形扩容方法,我也希望他们能这样做。
值得注意的是,欺诈和有效性证明执行层的设计范围非常广泛(所以不是所有的东西都需要 rollup)。对于大多数由一个应用程序或公司运行的低价值交易或商业交易等用例,validium 就是一个很好的解决方案。只有那些需要以太坊完整安全性的高价值去中心化金融产品才需要使用到 rollup,真的。随着像 adamantium 和 eigenDA 这样的诚实少数数据层想法的成熟,从长远来看,它们几乎可以和 rollups 一样安全。
我将跳过关于它如何工作的部分,因为 StarkWare 的 Gidi 以及 Vitalik 的说明比我更好。但要点是:你可以在一个 L2 上拥有 1000 个 L3、L4 或其他任何东西,而且所有的这些东西都可以用一个简洁的递归有效性证明来解决;只有这个需要在 L1 解决。因此,通过一个简洁的有效性证明进行验证,你就可以实现几百万的 TPS(如上所述,具有不同的属性)。因此,整个 "layer "的术语是相当有局限性的,如果我们达到 100,000 个服务器的目标,就会出现各种疯狂的结构。让我们只把它们看作是 rollups、validiums、volition 或其他什么,并讨论他们各自的安全属性。
现在则是来到了房间里的大象:可组合性。有趣的是,经过有效性证明的执行层可以与它的结算层单向地进行原子组合。要求是每个区块都生成一个证明(我们显然还没有达到这个要求,但这是可能的),证明生成是简单可并行的。因此,你可以让 L3 与 L2 进行原子组合。但问题是,你需要等待下一个区块的组合回来。对于许多应用程序来说,这根本不是问题,而且这些应用程序对于能够留在智能合约链上而感到愉悦。如果第 L2 提供某种形式的预先确认,这也有可能得到解决,所以 L3 和 L2 之间的交易实际上是可以原子组合的。
当你可以让多个排序器/节点组成一个统一的状态时,圣杯就成为战场争夺的中心了。我知道至少有 StarkWare、Optimism 和 Polygon Zero 的团队正在研究相关的解决方案。虽然我对实现这一目标所需的技术工程一无所知,但这似乎是在可能范围内的事情。事实上,Geometry 已经通过与 Slush 的合作在这方面取得了进展。
这就是真正的并行。一旦想通了这一点 —— 你实际上可以在对安全性和可组合性的做出最小妥协的情况下进行大规模的分形扩容。让我们回顾一下:你有 1000 个排序器组成一个统一的状态,一个简洁的有效性证明,这就是你需要验证所有这 1000 个排序器的全部东西。所以,你继承了以太坊的信任根,你保留了完全的可组合性,有些继承了完全的安全性,有些继承了部分安全性,但在每一种情况下,在可扩展性、安全性、可组合性和去中心化方面,都比运行 1000 个高度分散的单片 L1 有绝对巨大的净收益。
我预计今年晚些时候,第一批特定于应用的 L3 将通过 L2 StarkNet 上线。当然,我们将首先看到现有的 L2 会采取些行动。但是,真正的潜力将通过我们以前没有见过的新应用来释放,这些应用只有在分形扩容的情况下才真正可能实现。链上游戏或类似的项目,如Topology 的 Isaac 或Briq,可能会成为第一批部署自己的 L3 的项目。
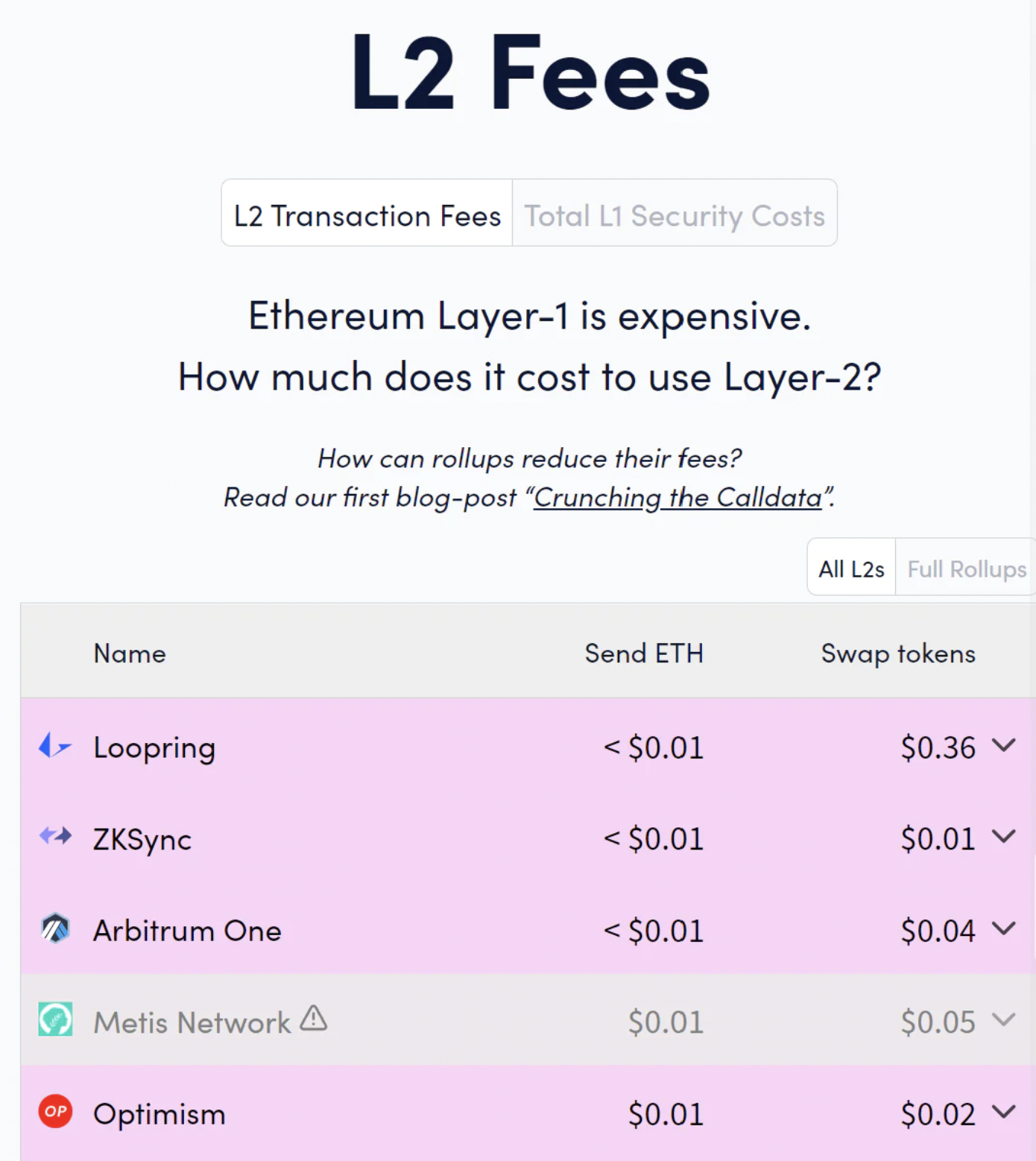
我们在这里谈论的是分形容,目前 rollup 费用是亚美分级别(实际上,Immutable X、Sorare 的费用更是低至 0.00 美元),但直到现在,它们也鲜少被利用。这也让我重回到了开始,重新来认识区块链领域的真正瓶颈 —— 新型应用。这不再是先有鸡还是先有蛋的问题了 —— 不管是昨天还是今天,我们都有大量的空区块空间,但是却没有需求。现在是我们应该专注于建立新颖的应用,独特地利用区块链的优势,并建立一些真正的消费者和企业需求的时候了。我还没有看到来自行业或投资者的足够承诺 —— 自 2020 年以来,应用层的创新几乎不存在。(将现有的 web2 概念克隆过来也毫无意义)不用说,没有这些应用,任何类型的扩容(分形或其他)都是资源浪费。
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表本站的观点或立场
您可能感兴趣
-
 欢迎来到新币圈:只不过这次,亏钱的地方叫股市
欢迎来到新币圈:只不过这次,亏钱的地方叫股市撰文:豆丸了2026 年 7 月 13 日,首尔。 韩国综合指数 KOSPI 单日暴跌 8.95%,年内第 7 次熔断。SK 海力士,韩国人眼里的"国运股",单日重挫 15.37%,近二十年没见过这么
-
 Meta 的 AI 账本:608 亿营收为何撑不住股价?
Meta 的 AI 账本:608 亿营收为何撑不住股价?Meta二季度营收608亿美元,创历史新高,同比增长28%。盘后跌7%。同一天发财报的微软,云业务超预期,盘后涨超8%。Meta的营收也超越了华尔街一致预期,广告收入594亿美元,增速27%,广告展示
-
 火币HTX《VIP守护者计划》|Yarra:守护每一次交易体验
火币HTX《VIP守护者计划》|Yarra:守护每一次交易体验《VIP守护者计划》是火币HTX推出的系列访谈栏目,聚焦大客户服务实践,每周二邀请平台一线服务团队分享真实服务经历、市场观察及客户需求洞察,传递长期主义的服务理念,展现火币HTX专业、稳健的客户服务能
-
 三星电话会:存储供不应求“明年比今年更紧张”,60-70%产能已分给长期协议,HBM4收入将占六成
三星电话会:存储供不应求“明年比今年更紧张”,60-70%产能已分给长期协议,HBM4收入将占六成作者:董静在生成式AI与Agentic AI(代理型AI)需求的强力驱动下,三星电子2026年第二季度交出了一份极具爆发力的答卷。 财报数据显示,三星电子当季实现营收171.5万亿韩元,同比暴增130
-
 美股芯片半导体跌跌不休,到底要回调到什么时候?
美股芯片半导体跌跌不休,到底要回调到什么时候?近来美股的存储芯片板块抛售,已经不能用单纯的"回调"两个字来形容了。昨晚,SK海力士、美光、闪迪这些昔日的芯片明星股继续集体下挫。费城半导体指数(SOX)从一个月前14,600多点的高位,一路跌到目前
-
 不发币、只收过路费:Visa 的稳定币算盘比发行方更狠
不发币、只收过路费:Visa 的稳定币算盘比发行方更狠作者:Chloe,ChainCatcherVisa 公布 2026 年第三季度财报,净营收 116 亿美元、同比增长 14%,季度内支付额首度突破 4 万亿美元,是公司历史上的第一次。但真正被市场放大
-
 早报|富达 Q3 信号报告:BTC、ETH、SOL 的净未实现盈亏均处历史低位,多项指标接近投降区间;韩国金融委拟提交统一数字资产法案,在野党同步推动废除加密税
早报|富达 Q3 信号报告:BTC、ETH、SOL 的净未实现盈亏均处历史低位,多项指标接近投降区间;韩国金融委拟提交统一数字资产法案,在野党同步推动废除加密税整理:ChainCatcher过去 24 小时发生了哪些重要的事? 泰国 SEC 指控 Bitkub 高管隐瞒 5000 万美元黑客损失,已提起刑事投诉 ChainCatcher 消息,泰国证券交易委
-
设立 Web3 专项小组,链上纠纷进入“正规军”调解时代") 加密行业每日观察:美国仲裁协会(AAA)设立 Web3 专项小组,链上纠纷进入“正规军”调解时代
加密行业每日观察:美国仲裁协会(AAA)设立 Web3 专项小组,链上纠纷进入“正规军”调解时代直击痛点:填补 Web3 商业纠纷的司法空白 过去,加密行业的纠纷往往因为智能合约的不可篡改性(Code is Law)和去中心化底层架构,难以在传统法庭获得有效且具备执行力的裁决。 为了彻底解决这一
- 成交量排行
- 币种热搜榜
 泰达币
泰达币 比特币
比特币 以太坊
以太坊 USD Coin
USD Coin Solana
Solana 瑞波币
瑞波币 Ronin Network
Ronin Network 币安币
币安币 World Liberty Financial USDv
World Liberty Financial USDv 莱特币
莱特币 艾达币
艾达币 狗狗币
狗狗币 大零币
大零币 Wormhole
Wormhole 比特现金
比特现金 SHIB
SHIB UNI
UNI OKB
OKB AR
AR ICP
ICP DOT
DOT LUNC
LUNC YGG
YGG DYDX
DYDX LPT
LPT ETC
ETC